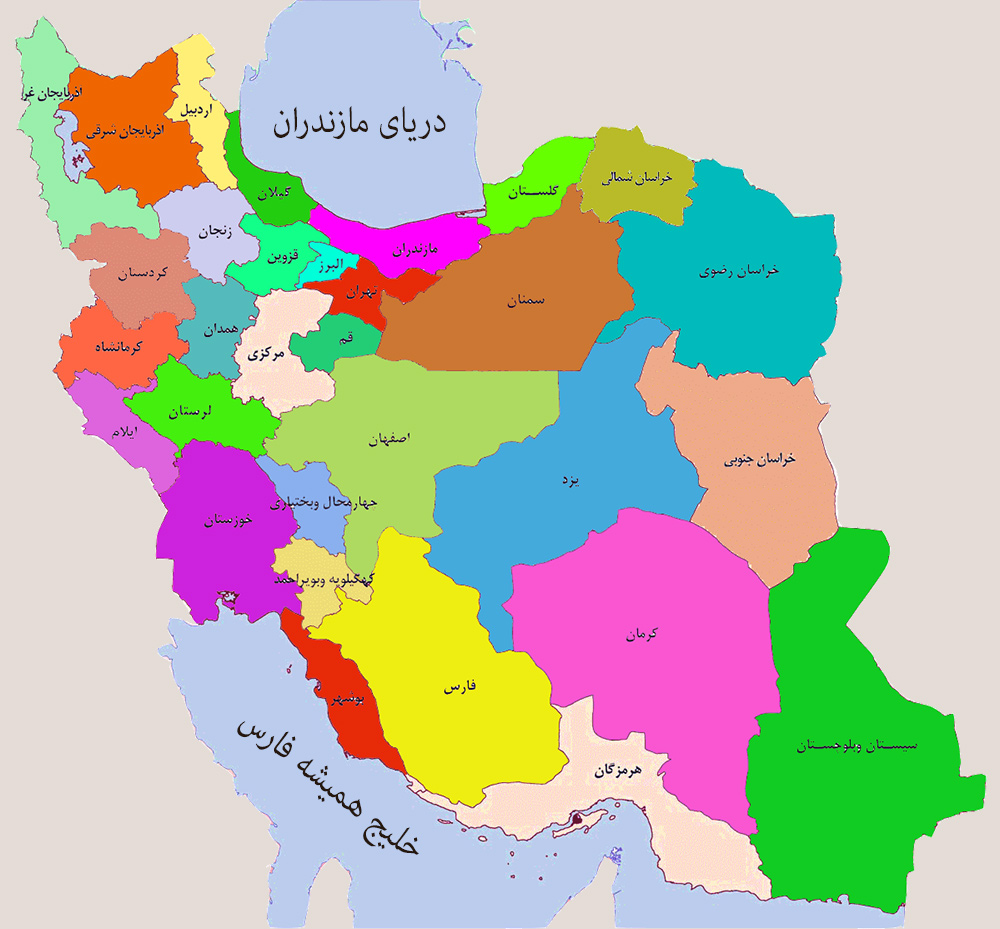
در مقاله قبلی گفتم که دو روش برای نمایش داده بر روی نقشه جغرافیایی وجود دارد. یکی استفاده از قابلیت Shape در اکسل و دیگری استفاده از پاور مپ (Power Map). در این مقاله بر روی نحوه نمایش دادهها بر روی نقشه با کمک پاور مپ میپردازم.

پاورمپ ابزاری است که اختصاصا برای گزارشها بر اساس دادههای جغرافیایی طراحی شده است. دادههای جغرافیایی ممکن است بر اساس طول و عرض جغرافیایی باشد یا بر اساس اسم شهرها، کشورها … باشد.
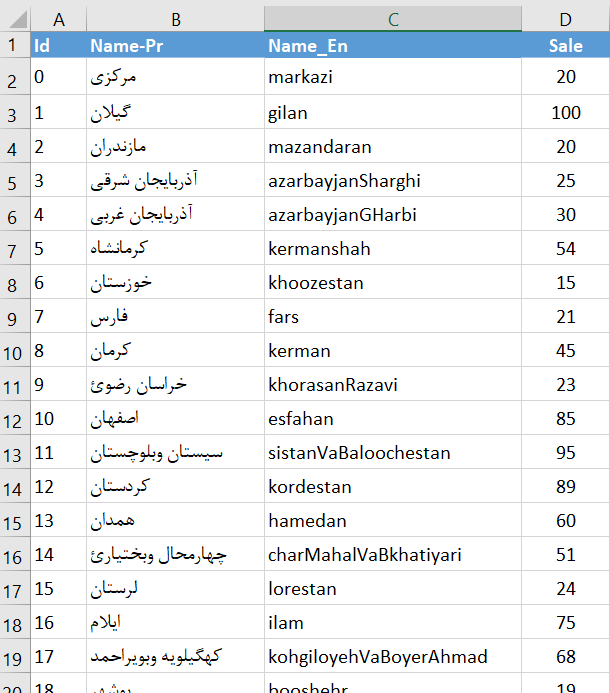
برای استفاده از پاور مپ به دو نکته دقت کنید. اول اینکه پاور مپ گزارشهای جغرافیایی را با کمک نقشههای موجود در سایت بینگ (Bing) نمایش میدهد بنابراین برای استفاده از این ابزار باید به اینترنت وصل باشید. دوم اینکه باید داده جغرافیایی در مجموعه داده وجود داشته باشد. این داده جغرافیایی ممکن است در قالب طول و عرض جغرافیایی باشد یا نام انگلیسی. به عنوان مثال برای نمایش مقدار فروش در مرکز هر استان باید یا طول و عرض جغرافیایی مرکز هر استان یا نام انگلیسی هر استان را مشخص کنیم.
برای پیدا کردن نام انگلیسی هر استان، از ویکی پدیا انگلیسی استفاده کردم. ابتدا لیست استانهای ایران به انگلیسی را در ویکی پدیا انگلیسی سرچ کردم و سپس با طی کردن مراحل زیر، اسامی انگلیسی استانها و مراکز آن را به همراه مساحت، جمعیت و تراکم جمعیت به صفحه اکسل اضافه کردم.
۱-از منو Data، گزینه New Query و سپس گزینه From Other Source و در نهایت From Web را انتخاب کردم.
۲-آدرس ویکی پدیا انگلیسی مربوط به استانهای ایران را درکادر نمایش داده شده وارد کردم. بعد از کلیک Ok لیستی از جداول موجود در صفحه وب نمایش داده شد. جدول مربوط به لیست استانهای ایران را انتخاب کردم و بعد هم گزینه Load را کلیک کردم. لیست استانهای ایران به همراه مراکز، جمعیت و تراکم آن، به فایل اکسل اضافه شد.
در مرحله بعدی باید دادهها پاکسازی شود. اولا که تعدادی از ستونها اضافی است، آنها را پاک کردم و بعد هم اینکه در برخی ستونها اطلاعات اضافی هست که باید پاک شود. به عنوان مثال در ستون مساحت، مقدار km هم ذکر شده است که باعث عدم نمایش درست دادهها میشود. برای پاکسازی دادهها مراحل زیر را طی کردم.
۱-ستونهای Map و Note را که اطلاعات مهمی نداشتند را پاک کردم.
۲-از ستون Data گزینه From Table را انتخاب کردم. این کار باعث میشود که دادههای موجود در جدول جاری به محیط Power Query منتقل شود. پاکسازی داده در محیط Power Query به سادگی انجام میشود.
۳-ستون مساحت (Area) دادهای مشابه ۵,۸۳۳ km2(2,252 sq mi) دارد. این داده برای محاسبه مناسب نیست چون ترکیب کاراکتر و عدد است و برای تهیه گزارش فقط به عدد احتیاج داریم. بنابراین بر ستون Area کلیک میکنم و بعد گزینه Split را انتخاب میکنم. این گزینه، ستون جاری را بر اساس یک جداکننده به دو ستون تبدیل میکند. گزینه Custom را انتخاب کردم و در کادر باز شده مقدار km را وارد کردم و به این صورت به پاور کوئری گفتم که این ستون را به دو ستون تبدیل کن. یک ستون قبل از km و یک ستون بعد از km. بعد هم ستونی که حاوی km و مقادیر بعد از آن بود را پاک کردم.
۴-همین کار را برای ستون تراکم (Density) هم انجام دادم. با این تفاوت که “/” را به عنوان جداکننده معرفی کردم.
۵-در نهایت هم Load&Close را انتخاب کردم.
دقت کنید که فرمت ستونهای تراکم، مساحت، جمعیت و تعداد شهرستان Number باشد. اگر که نبود حتما فرمت آنها را به Number تغییر دهید.
در مرحله آخر، برای نمایش دادهها بر روی نقشه (پاورمپ) باید دادهها را به Power Map (پاور مپ) اضافه کرده و تنظیمات لازم را انجام دهم. برای انجام این کار مراحل زیر را انجام دادم.
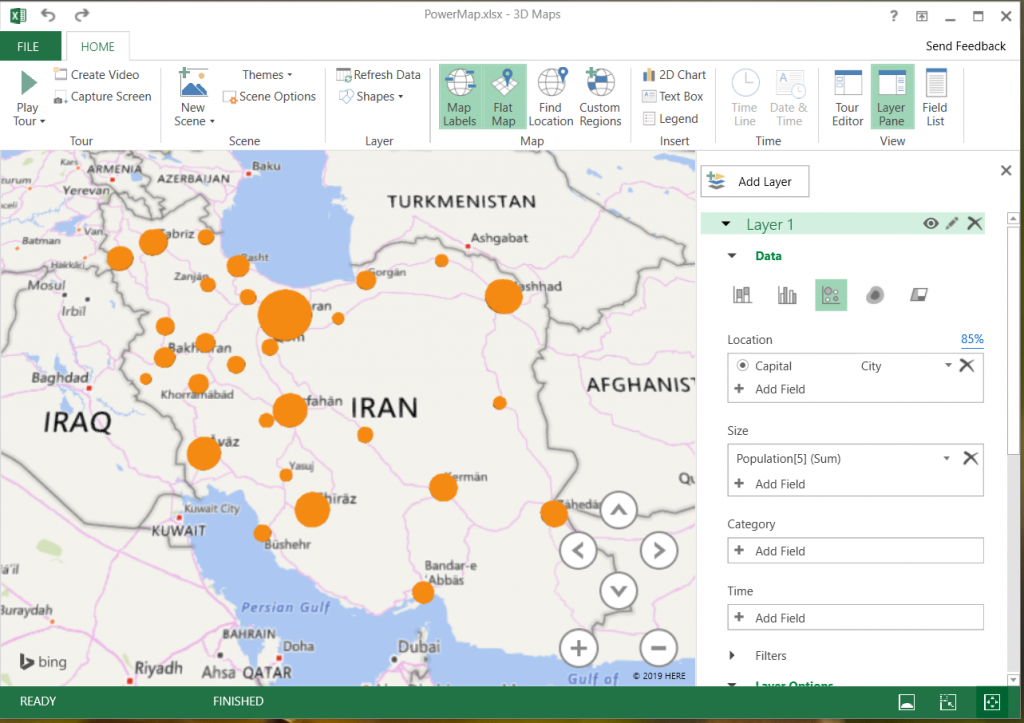
۱-از منو Insert گزینه ۳D Maps را انتخاب کردم. با انجام این کار دادهها به فضای پاورمپ اضافه میشود.
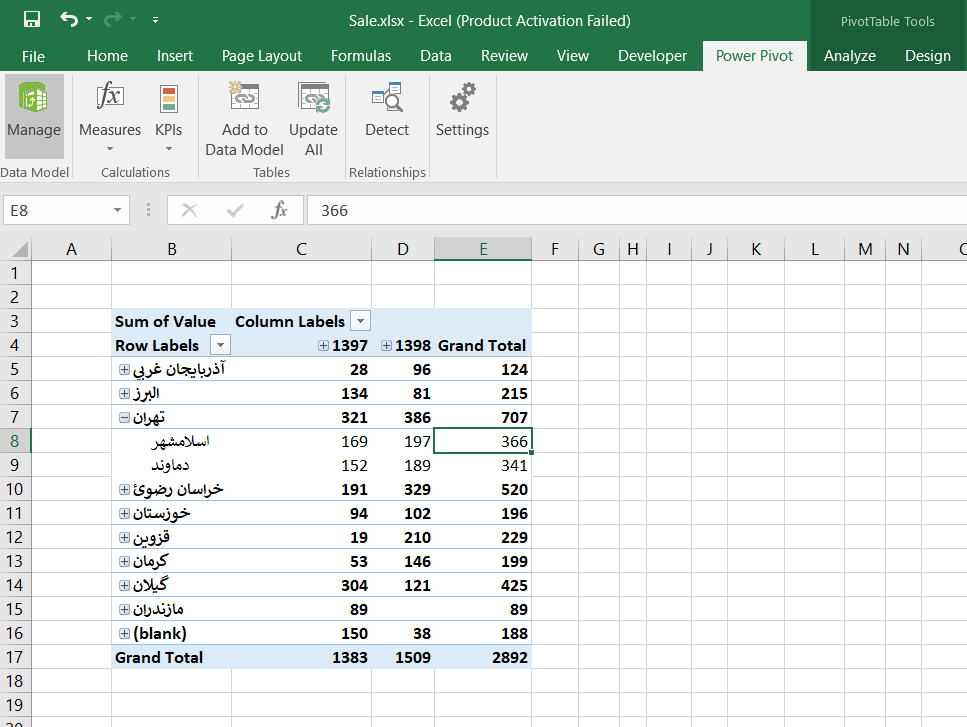
۲-ستونی در سمت راست نمایش داده میشود. در قسمت Location، گزینه Add Field را انتخاب کرده و سپس گزینه Capital را انتخاب کردم. با این کار برای پاور مپ لیست مشخص کردم که لیست نقاط جغرافیایی مورد نظر من بر اساس ستون Capital است. ستون Capital در این مثال به مرکز استان اشاره میکند.
۳-بعد از آن باید مقداری که در هر استان نمایش داده شود را مشخص کنم. در مرحله اول قصد دارم که مساحت هر استان بر روی نام آن نمایش داده شود. بنابراین در قسمت Height، گزینه Add Filed و بعد Area را انتخاب کردم.
۴-نحوه نمایش دادهها به صورت پیش فرض میلهای است. نحوه نمایش را به حبابی تغییر میدهم. نمودار حبابی بر روی نقشه خواناتر است. اندازه هر حباب بسیار بزرگ بود و خوانایی گزارش را کاهش داده بود. بنابراین از قسمت Option، گزینه Size را انتخاب کردم و سایز را کاهش دادم. این کار باعث شد تا مقیاس نمایش حبابها کوچک تر شود.
۵- با کلیک بر روی Map Labels نام هر شهر بر روی نقشه نمایش داده میشود.
۶-در صورتی که موس را بر روی هر حباب(دایره) نگه دارید، نام نقطه جغرافیایی و مساحت آن استان نمایش داده میشود.
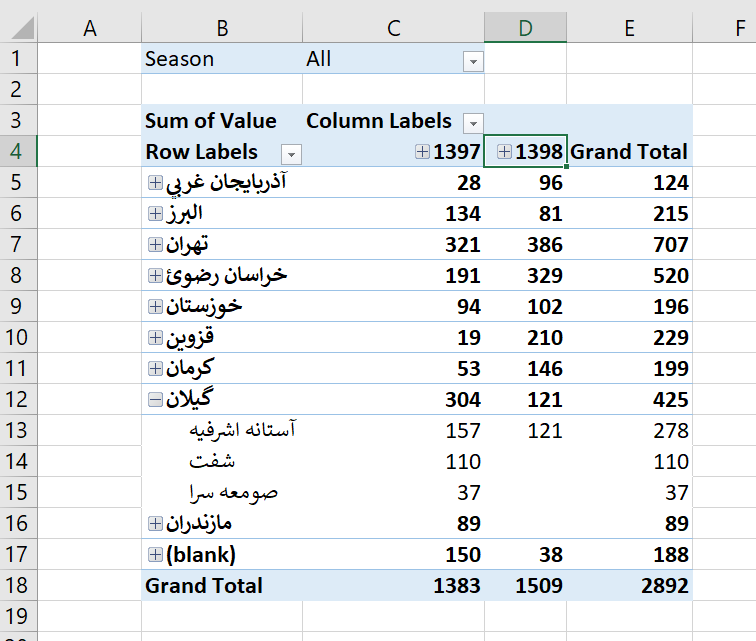
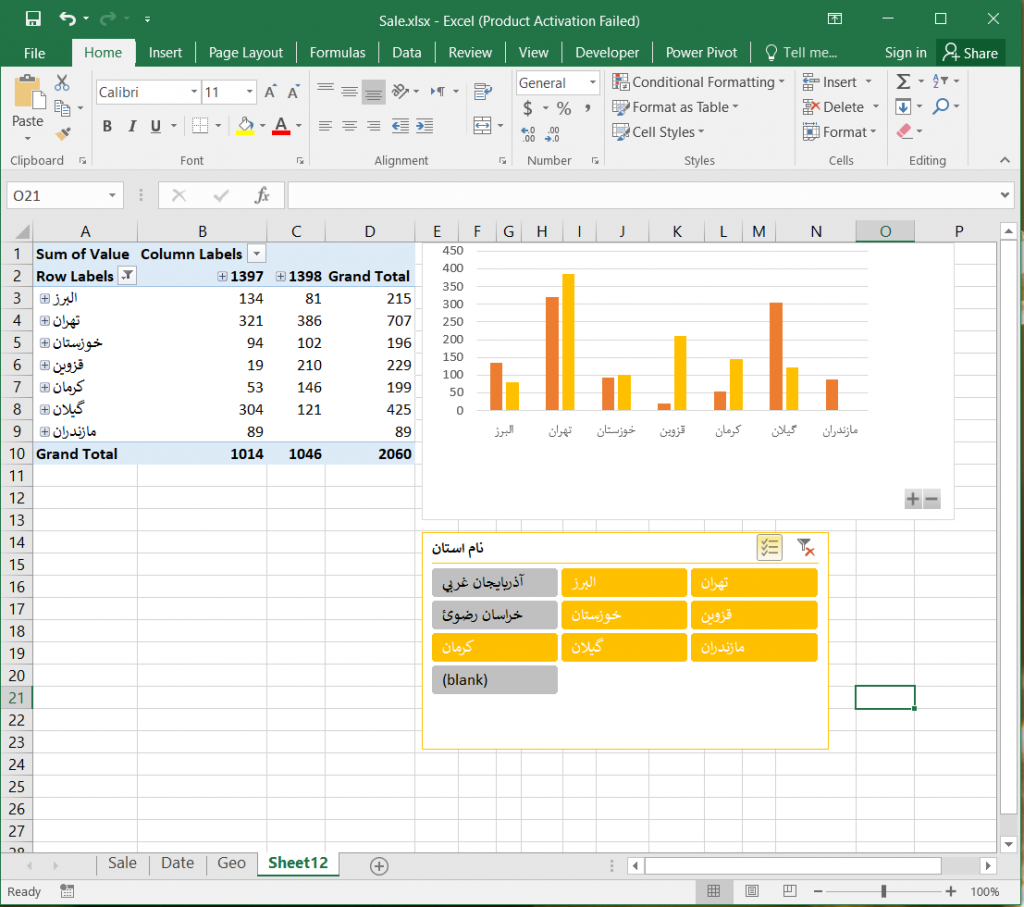
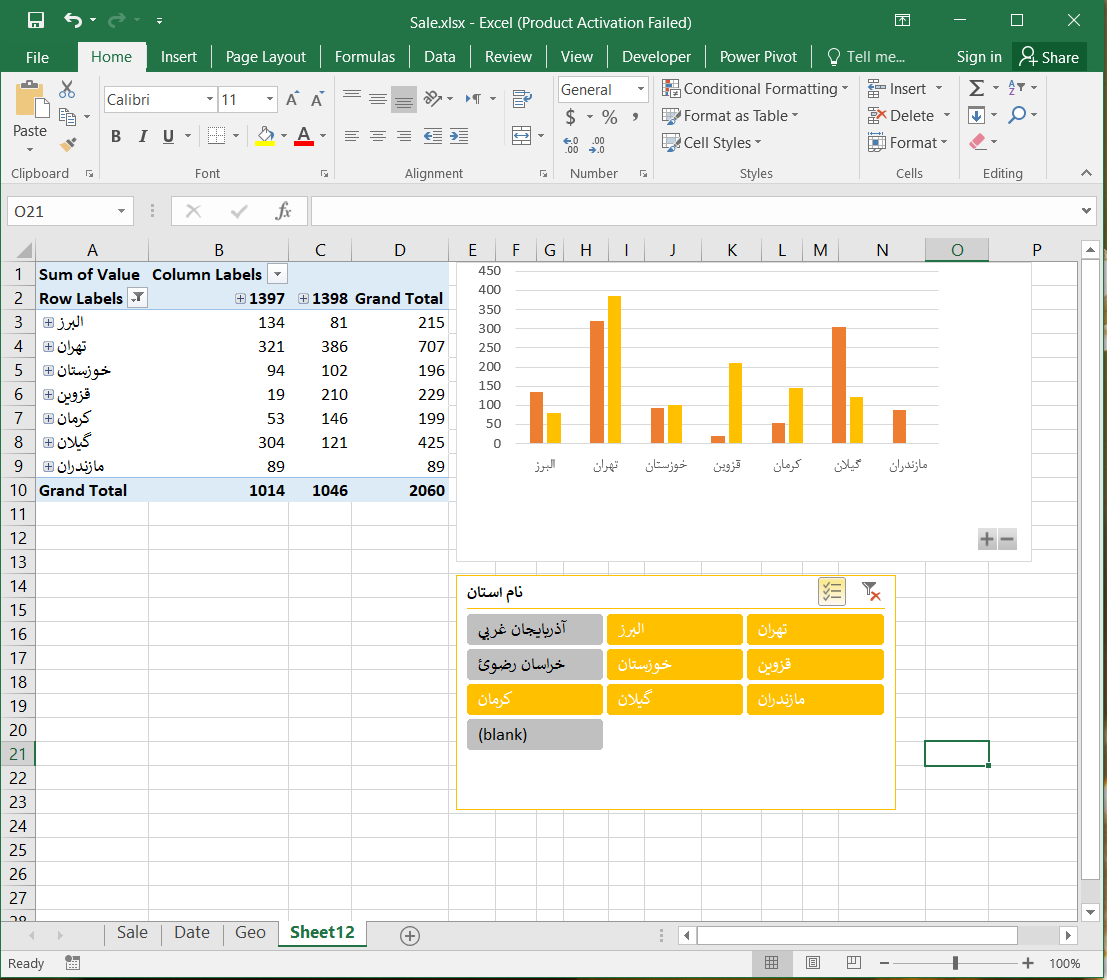
میتوانید مقدار فروش در هر استان را با مساحت یا جمعیت استان جایگزین کنید و گزارش مقدار فروش در هر استان را بر روی نقشه نمایش دهید.