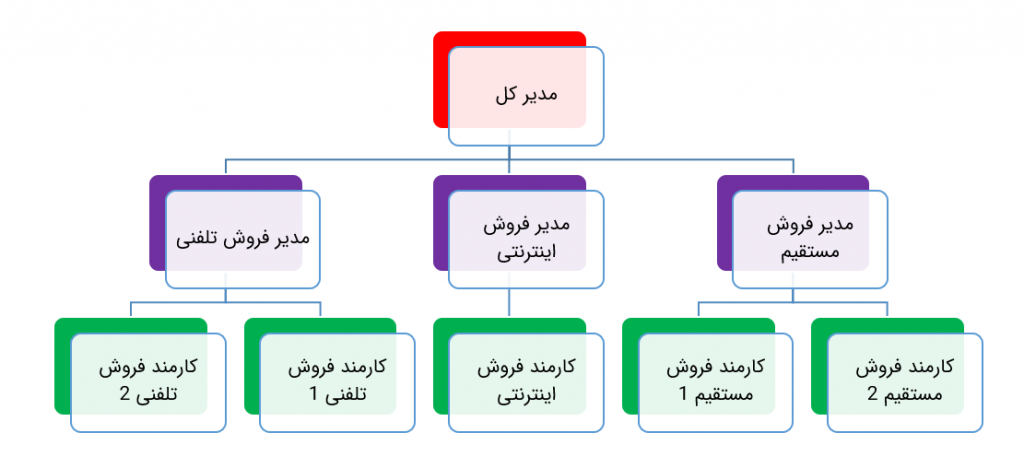
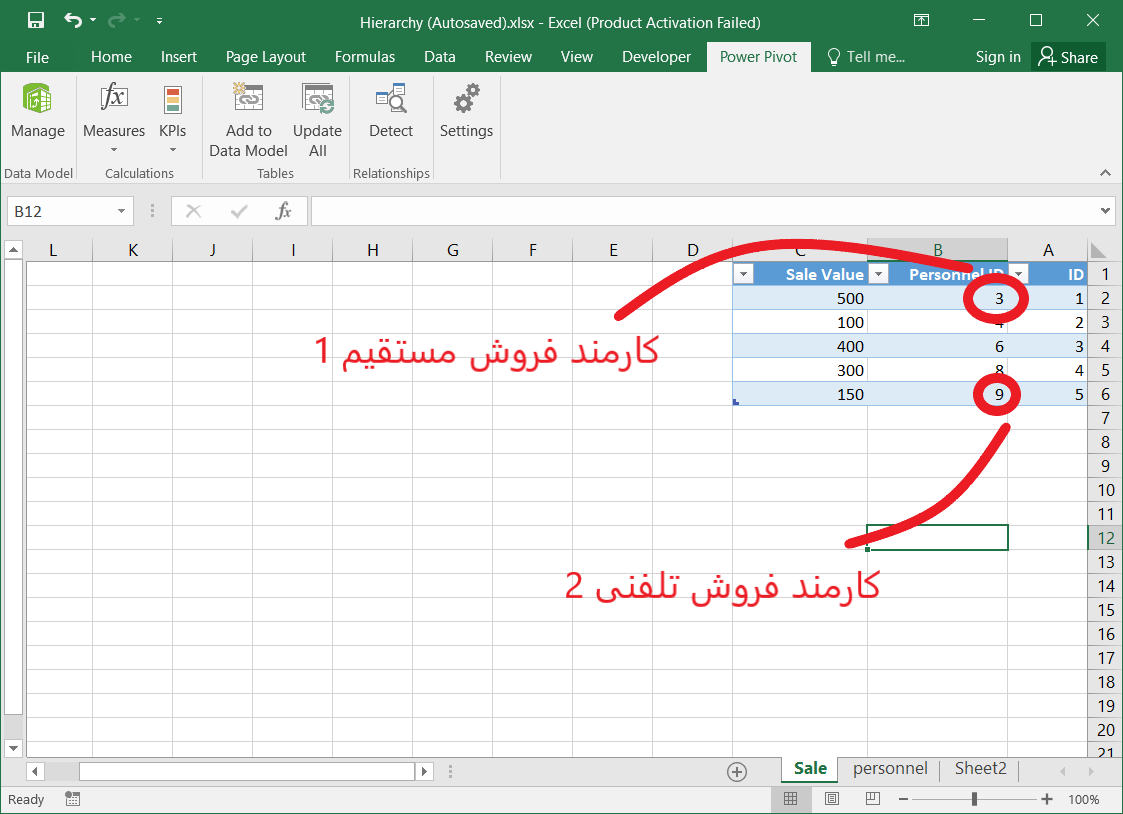
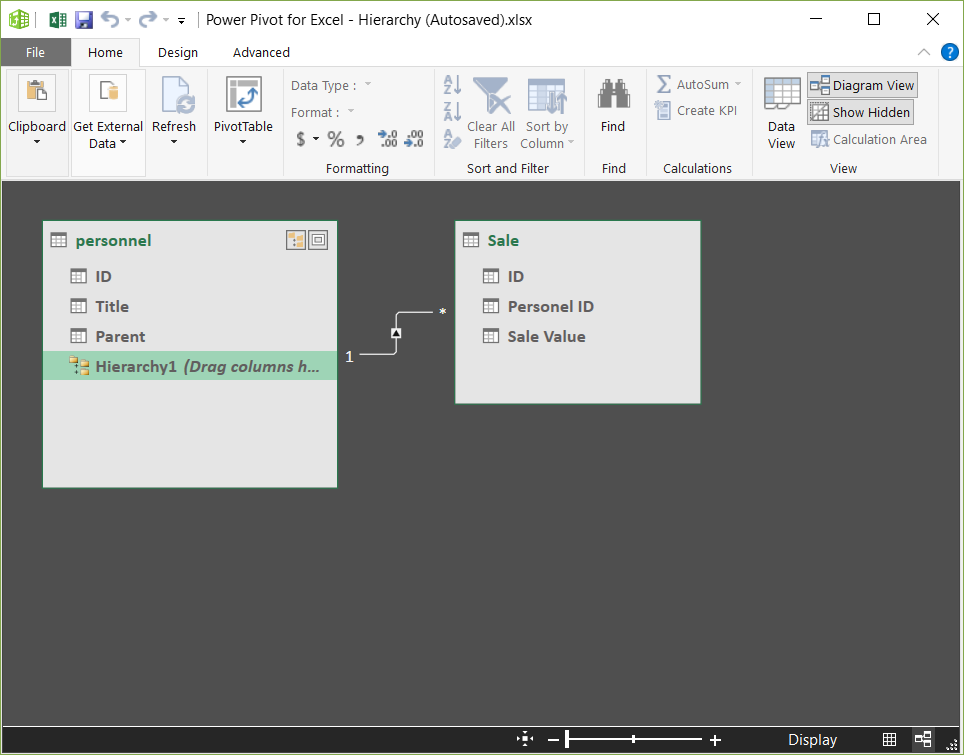
در مقاله سلسله مراتب در هوش تجاری به تعریف سلسله مراتب پرداختیم و گفتیم که سلسله مراتب یکی از راههای دسته بندی و پیماش داده است و اغلب برای دادههایی که ذات سلسله مراتبی دارند مانند سلسله مراتب اداری (مدیرعامل/مدیر میانی/کارمند)، تاریخ (سال/فصل/ماه/روز)، جغرافیا (کشور/استان/شهر) … مورد استفاده قرار میگیرد.
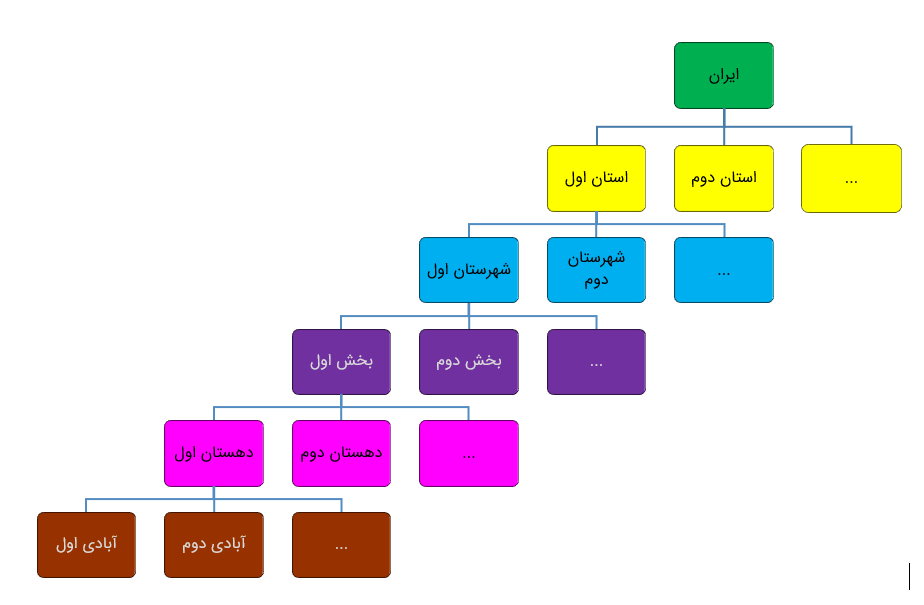
در این مقاله قصد دارم سلسله مراتب جغرافیایی ایران را بررسی کنم. برای این کار در ابتدا باید تقسیمات کشوری ایران را پیدا میکردم. طیق تعریف ویکی پدیا، کشور ایران به چندین استان و هر استان به چند شهرستان و هر شهرستان به تعدادی بخش و هر بخش به چند دهستان و هر دهستان به تعدادی آبادی تقسیم میشود. بنابراین تصویر شماتیک سلسله مراتب جغرافیایی ایران به شکل زیر خواهد بود.

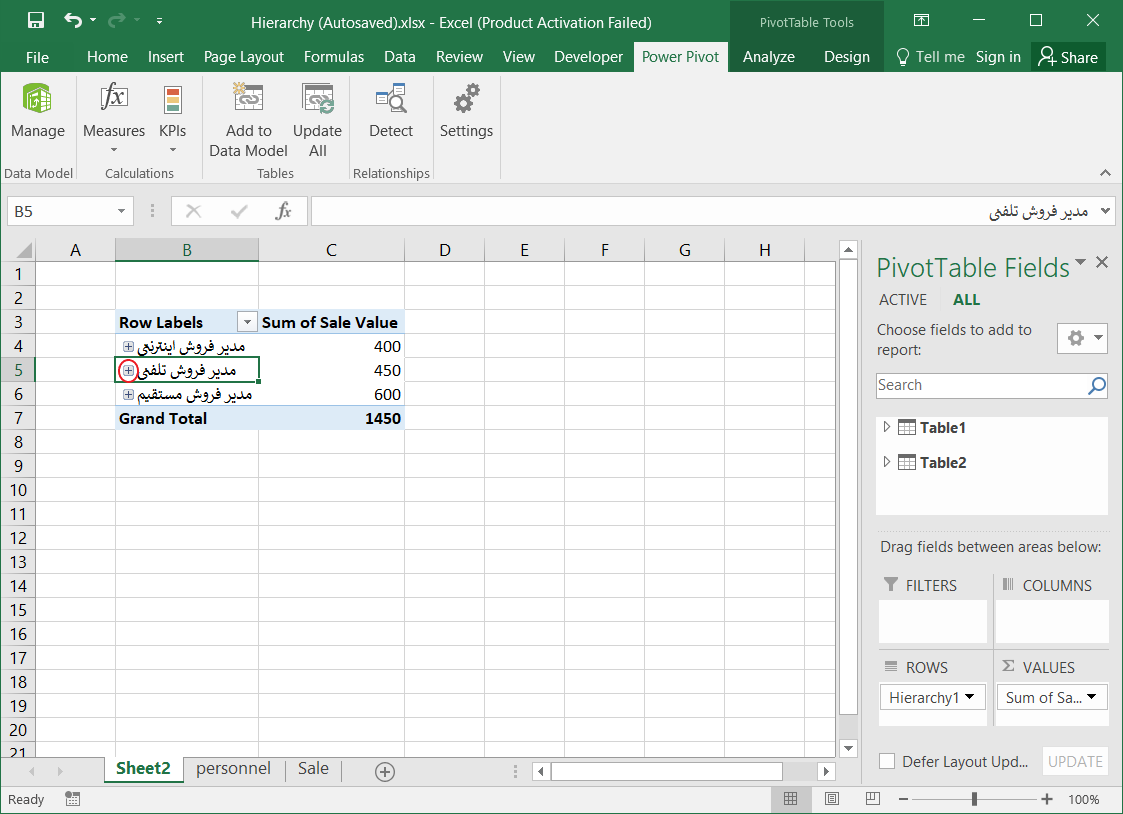
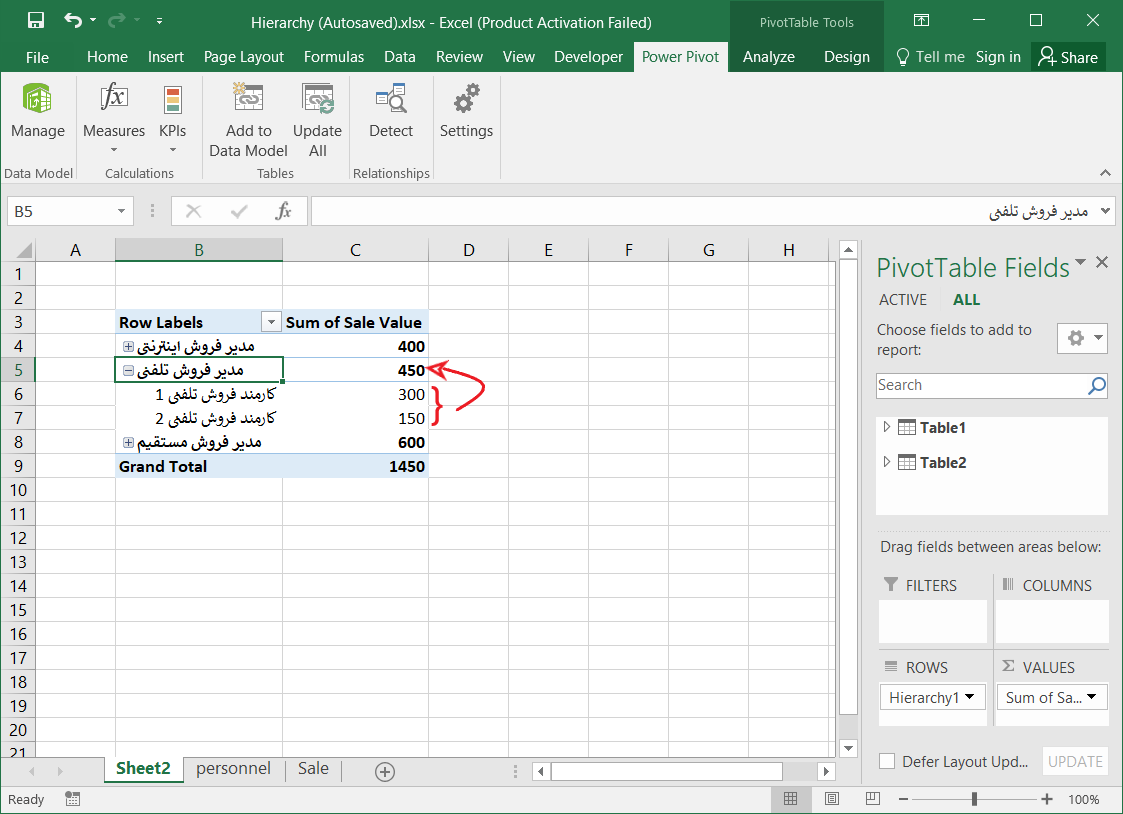
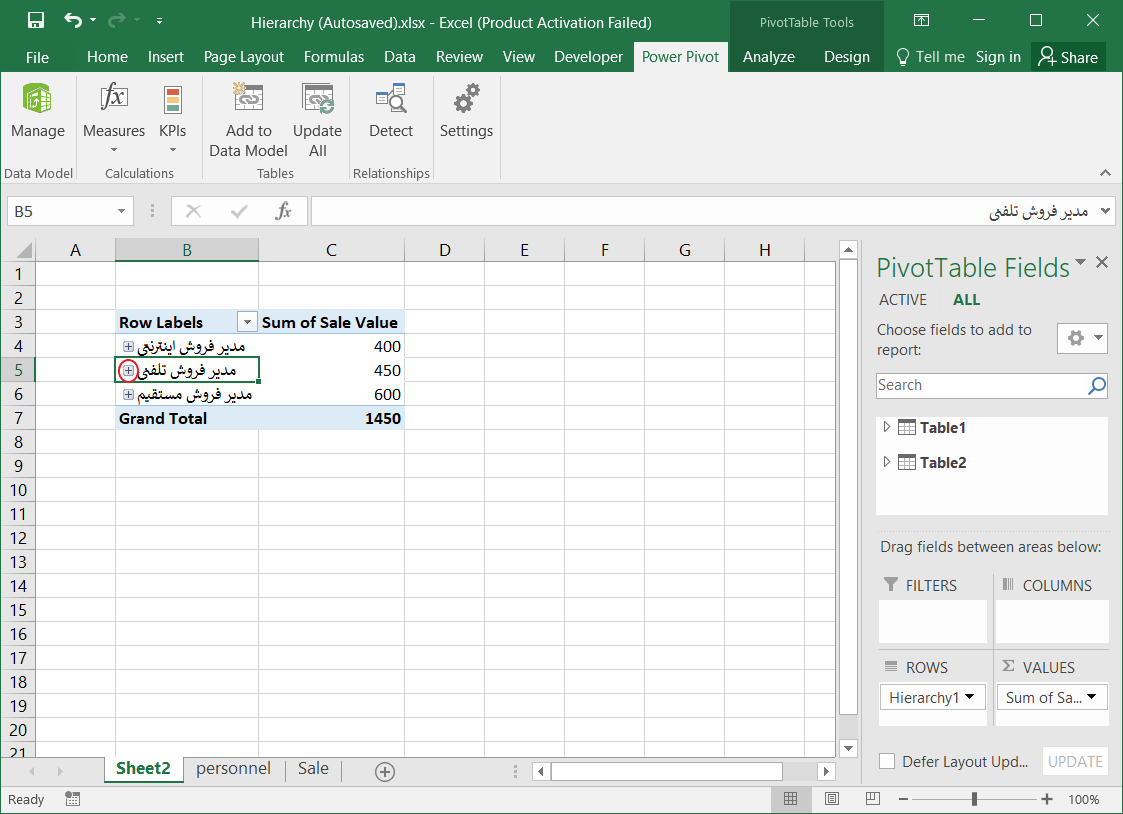
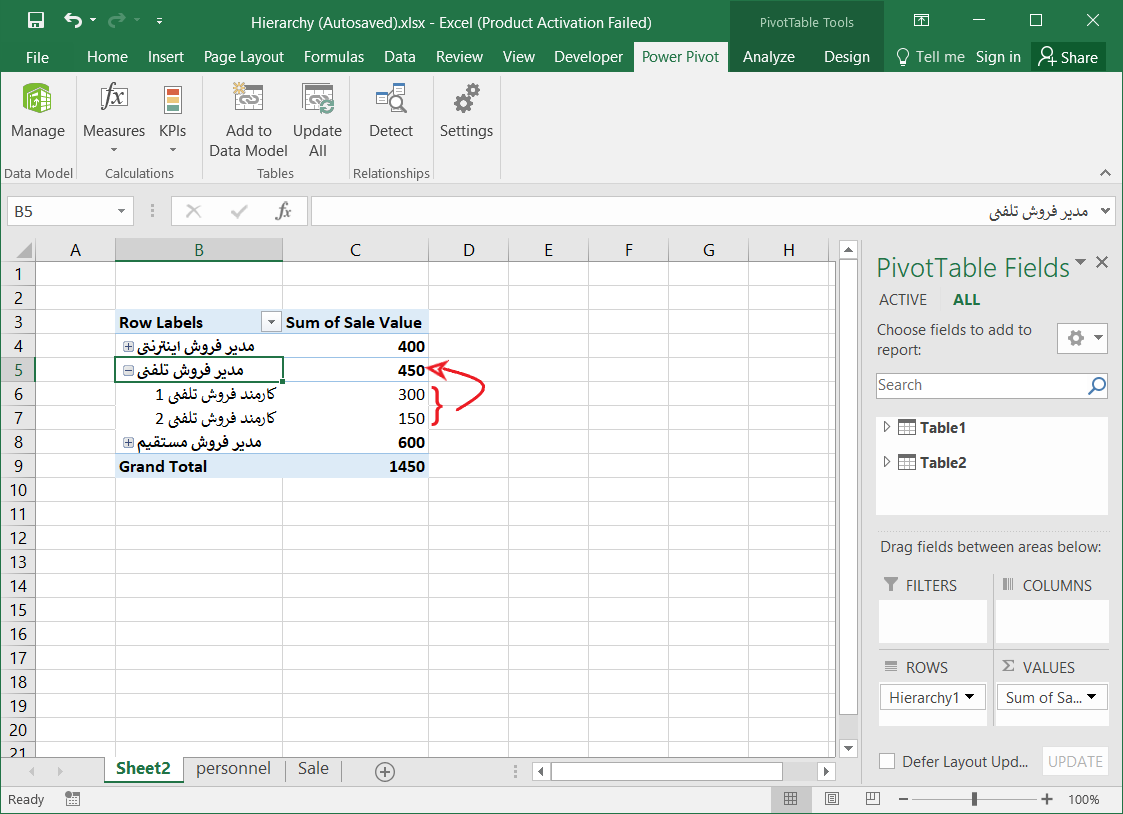
قصد دارم که در نهایت به ساختار سلسه مراتبی به صورت زیر برسم که در آن با کلیک بر روی علامت + کنار هر منطقه جغرافیایی، زیر مجموعههای آن را مشاهده کنم. به عنوان مثال در فایل زیر، بر روی استان تهران کلیک کردم. شهرستانها، بخشها، دهستانها و آبادیهای این استان نمایش داده شد.
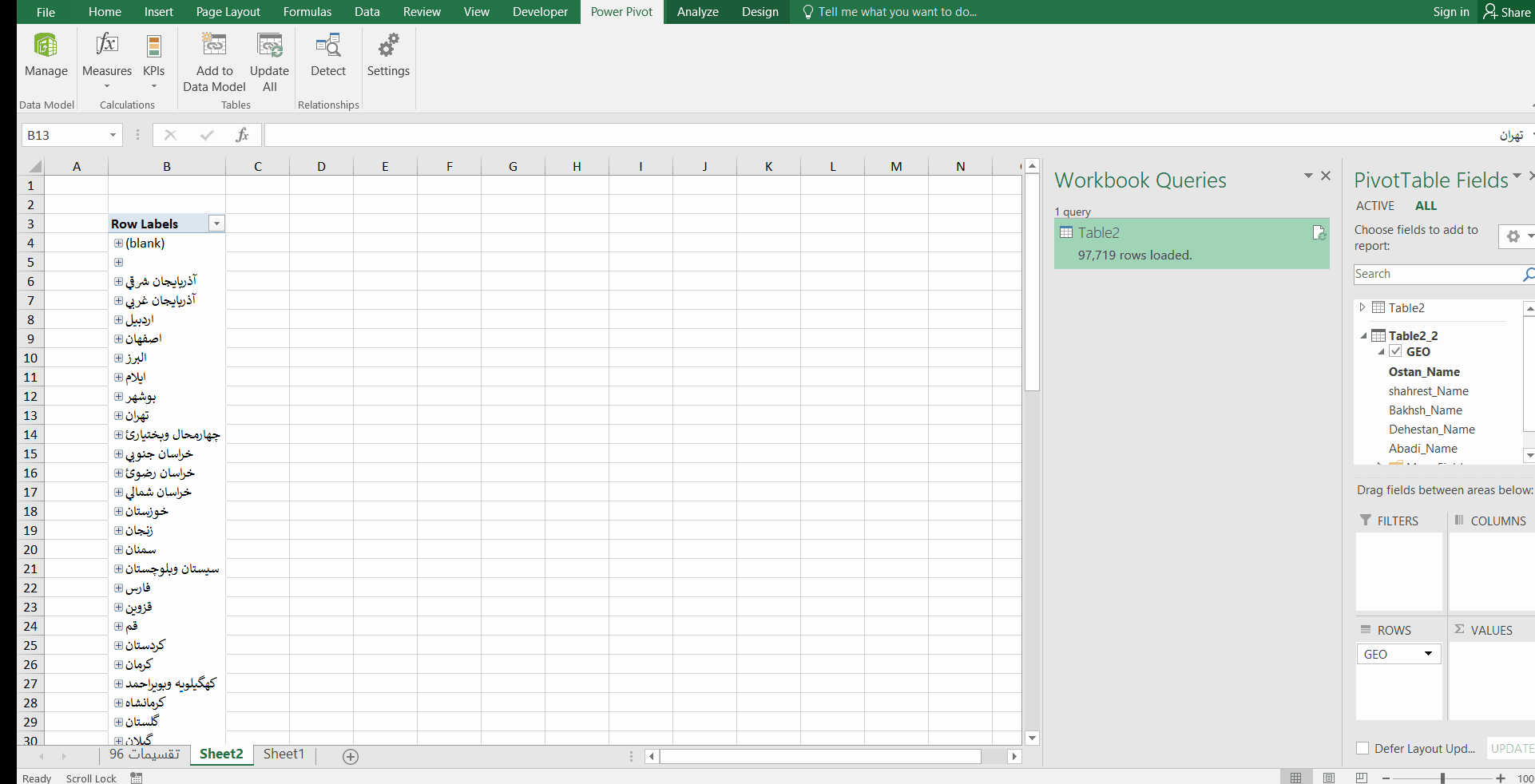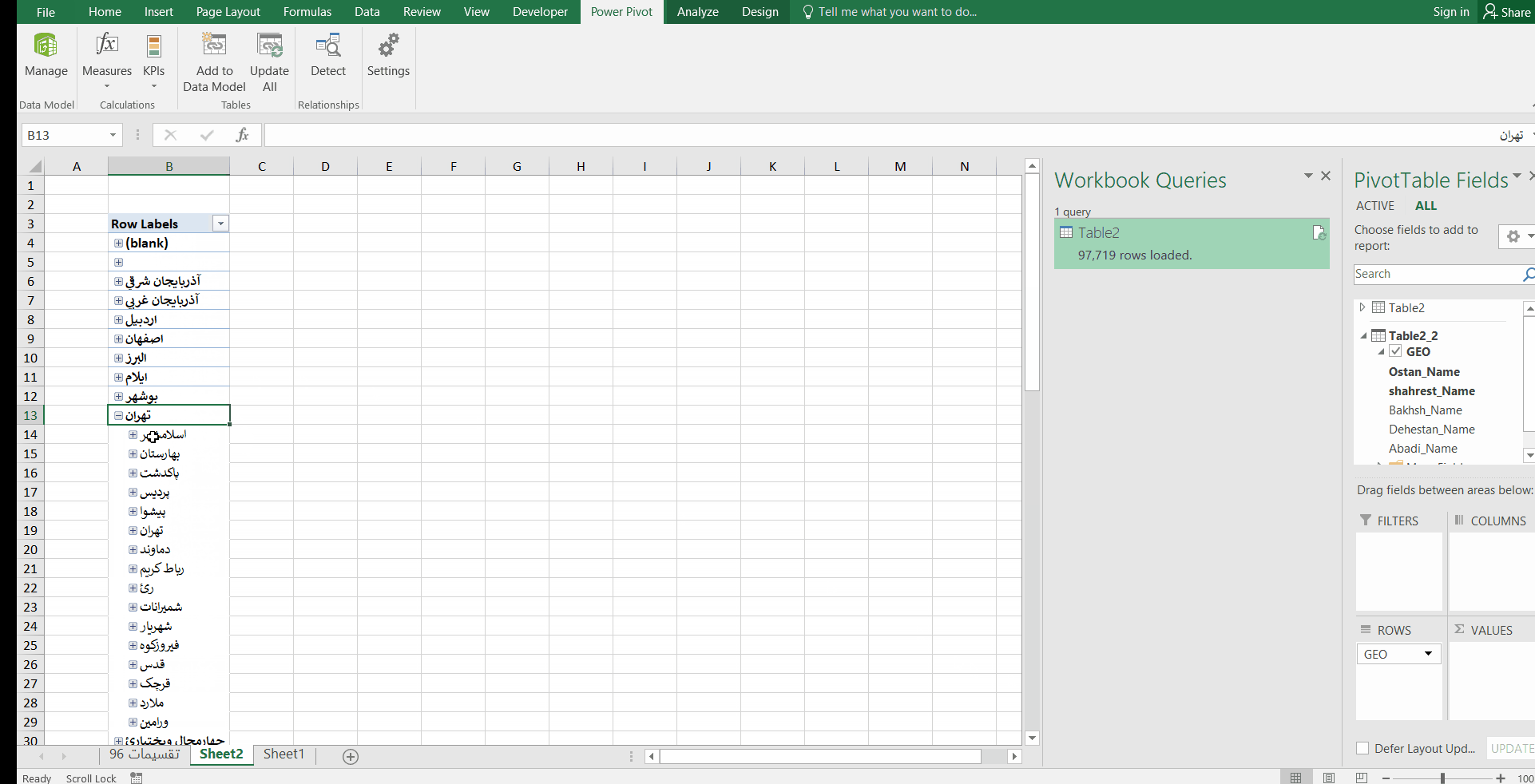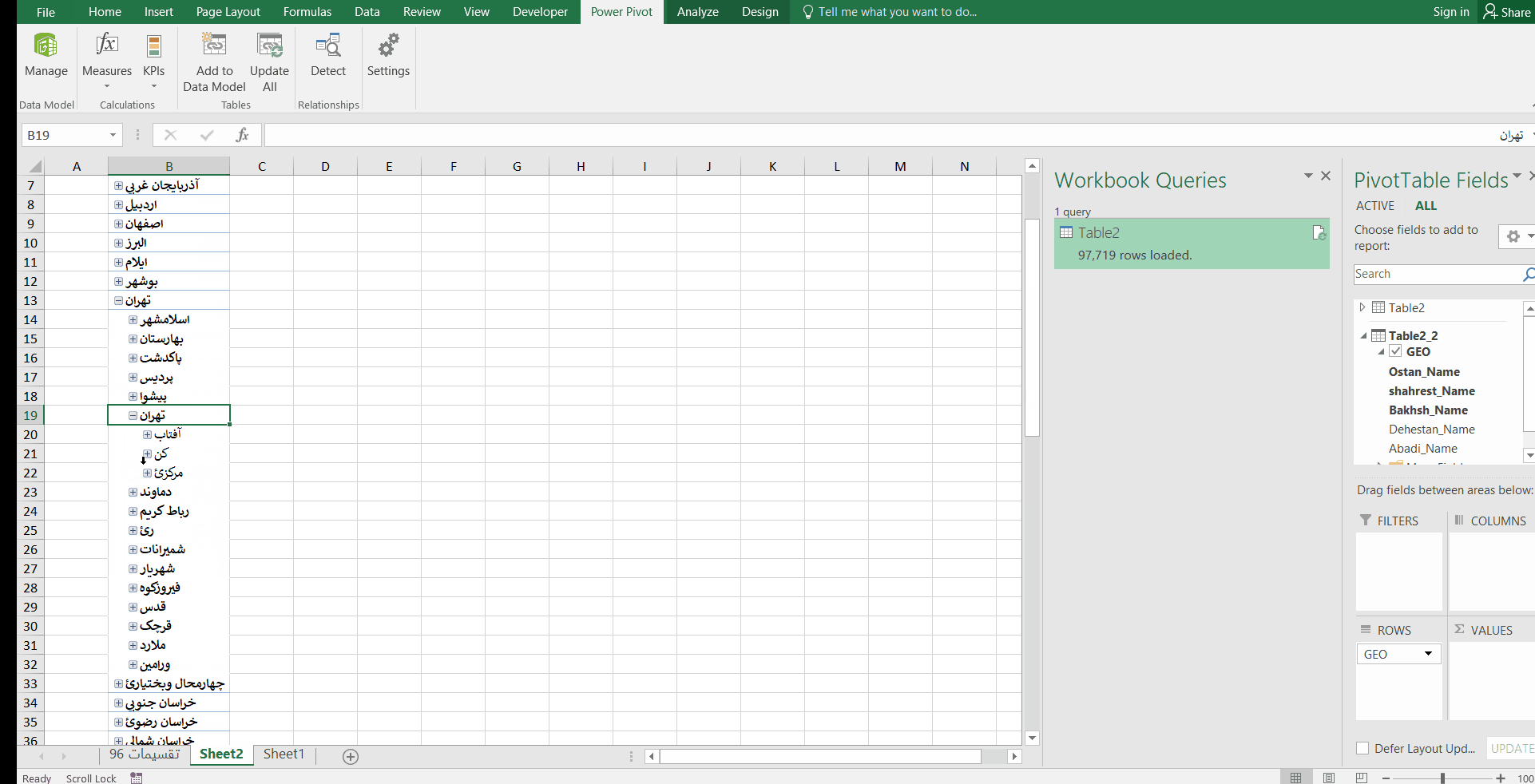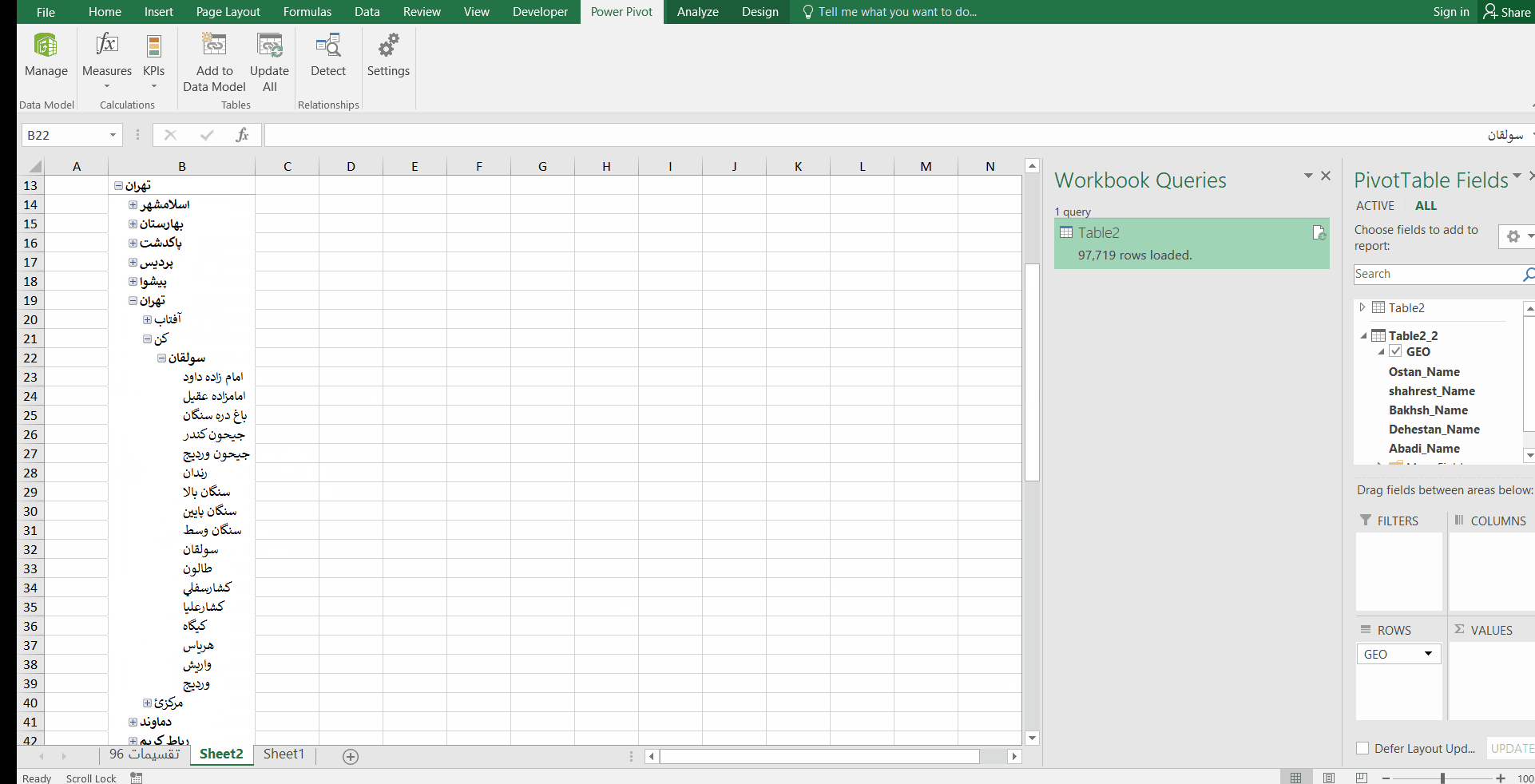

این ساختار سلسله مراتبی میتواند به دادههای فروش، تعداد پرسنل، میزان تولید …. وصل شود. مثلا تعداد کل فروش در هر استان در مقابل آن نمایش داده شود، سپس با کلیک بر روی علامت + کنار نام هر استان، مقدار فروش در هر شهرستان آن استان نمایش داده شود و الی آخر.
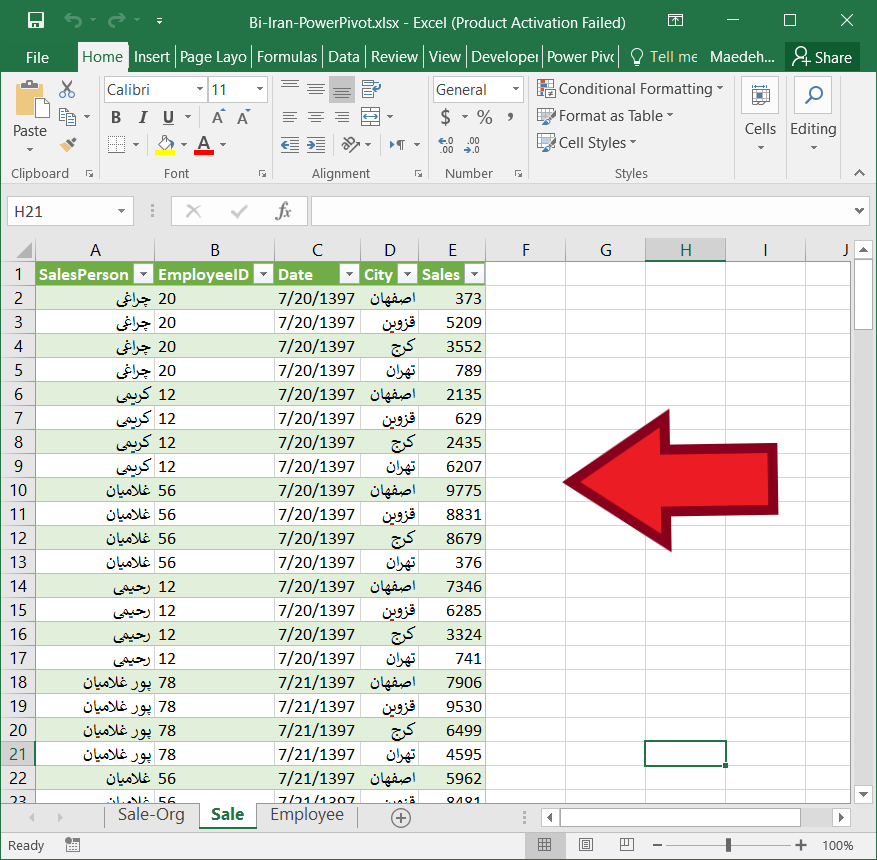
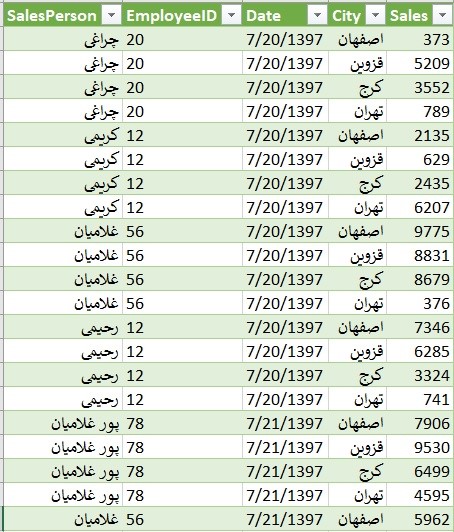
برای تهیه سلسله مراتب جغرافیایی ایران باید لیست استان، شهرستان، بخش، دهستان و آبادی ایران را پیدا میکردم. بنابراین دست به دامن گوگل شدم و از سایت آمار ایران اکسل فایل تقسیمات کشوری ایران برای سال ۹۶ را پیدا کردم. فایل مشابه تصویر زیر بود. این فایل را از اینجا هم میتوانید دانلود کنید.

نام تقسیمات کشوری استان، شهرستان، بخش، دهستان، آبادی را تصویر فوق مشاهده میکنید. برای هر تقسیم کشوری دو ستون تخصیص یافته است یکی برای نام و دیگری کد مربوط به آن.
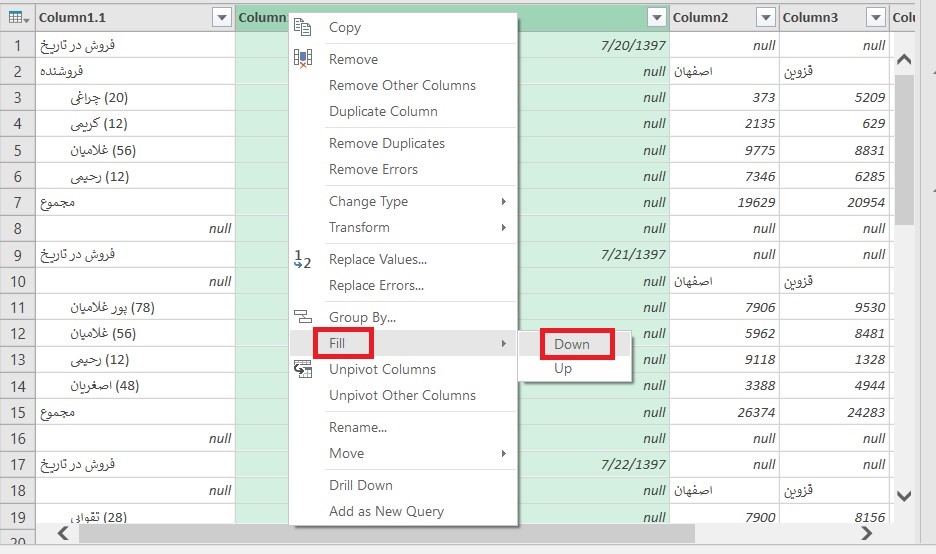
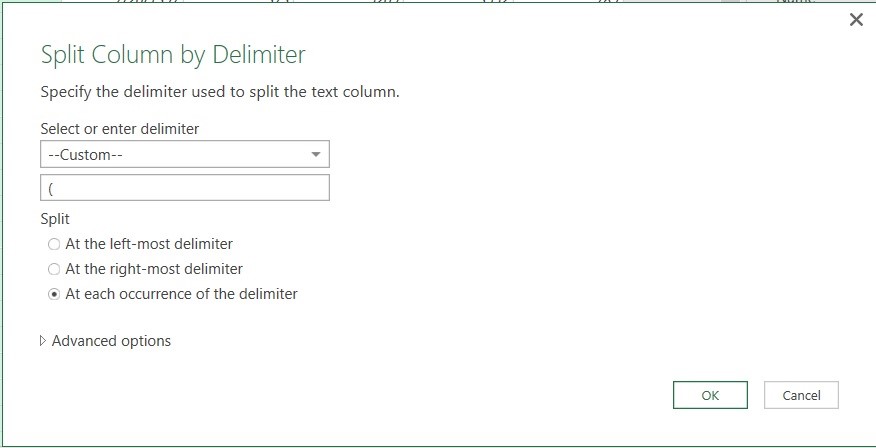
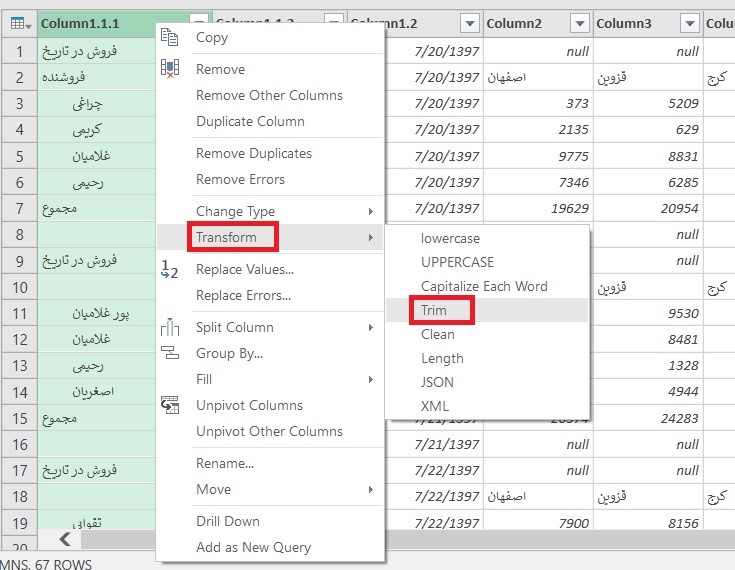
شهر (در اکسل فوق با نام City) در تقسیمات اصلی کشور وجود ندارد و همانطور که در تصویر میبینید اکثر سلولهای مربوط به City خالی است. آنچه که ما به نام شهر میشناسیم در تقسیمات کشوری به نام شهرستان شناخته شده است. بنابراین من دو ستون City و City_Name را پاک کردم.
دو ستون آخر هم برای ساخت سلسله مراتب مورد استفاده قرار نمیگیرد، بنابراین آنها را هم پاک کردم.

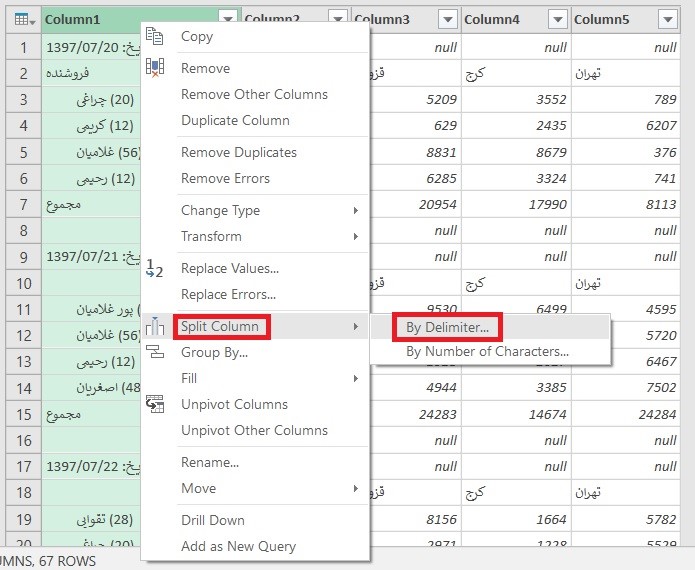
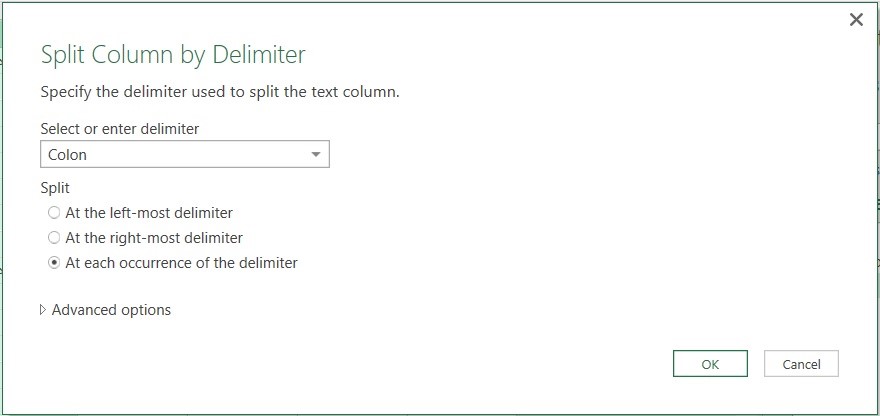
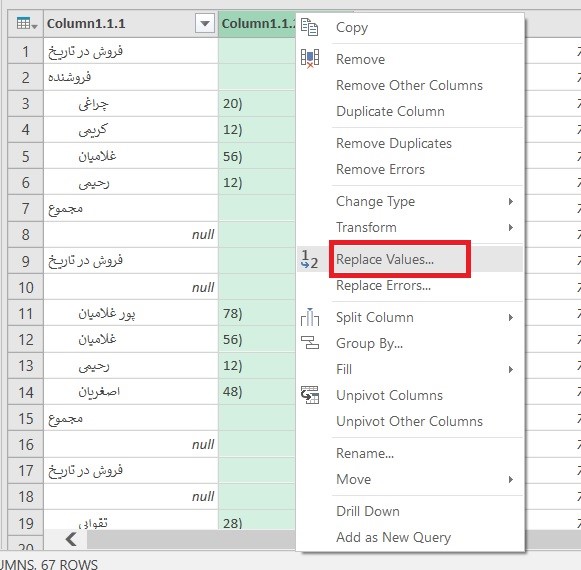
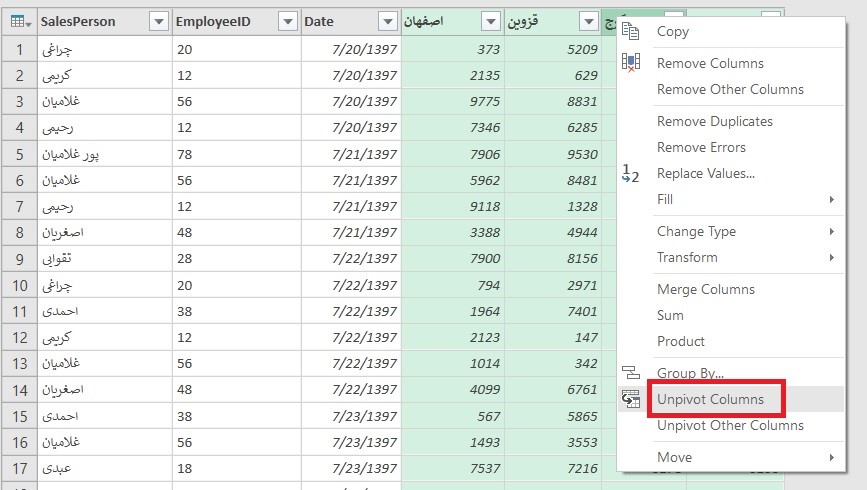
اگر که به دادهها دقت کنید، تعدادی سلول خالی مشاهده میکنید. این سلولها لازم نیستند و بهتر است که دادهها پاکسازی شده و سلولهای خالی حذف شوند. جهت حذف این سلولها از پاور کوئری استفاده کردم. برای انجام این کار، مراحل زیر را طی کردم:
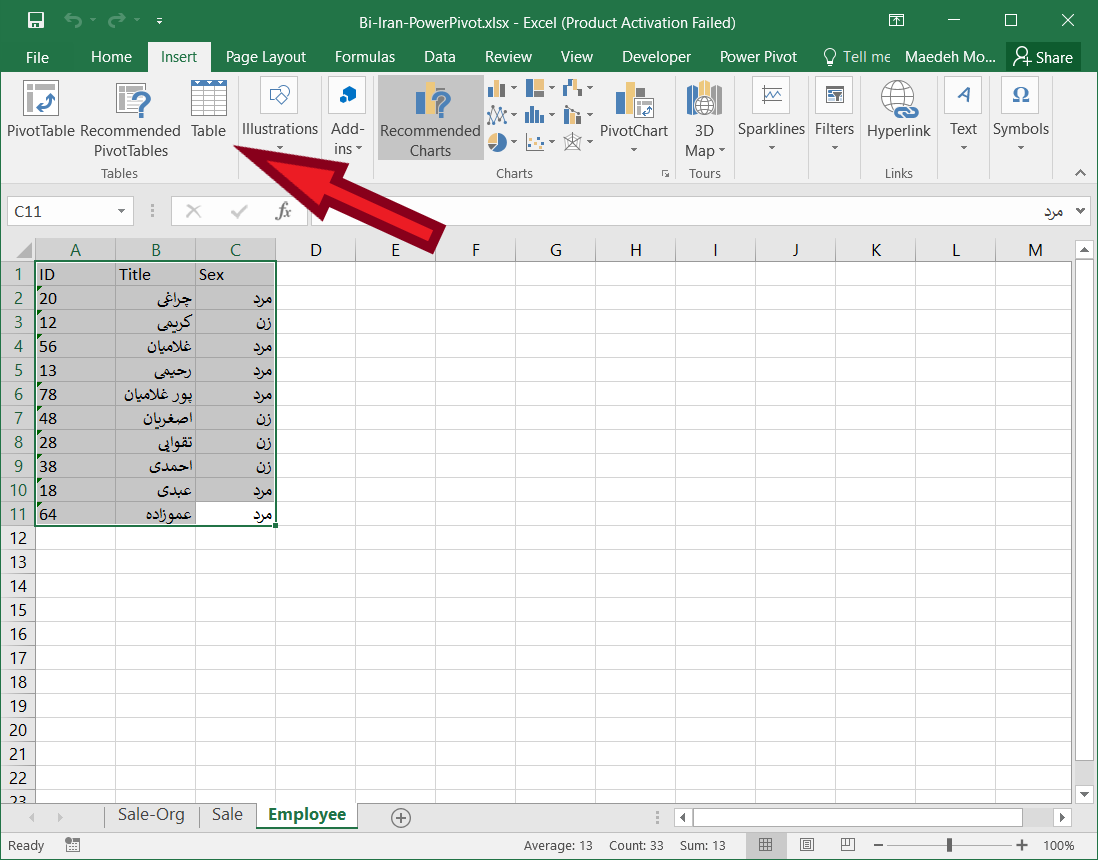
۱- تمام داده ها را انتخاب کرده و از تب Insert گزینه Table را انتخاب کردم.
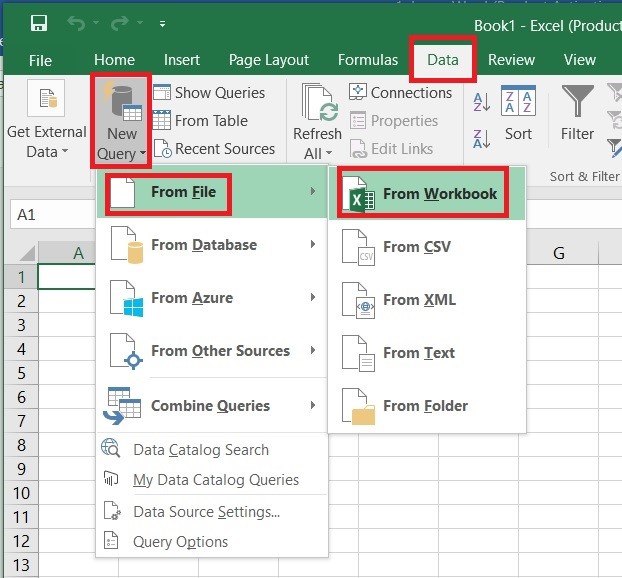
۲- همانطور که دادهها در حالت انتخاب بودند، از تب Data گزینه From Table را انتخاب کردم تا دادهها به فضای پاور کوئری اضافه شود.
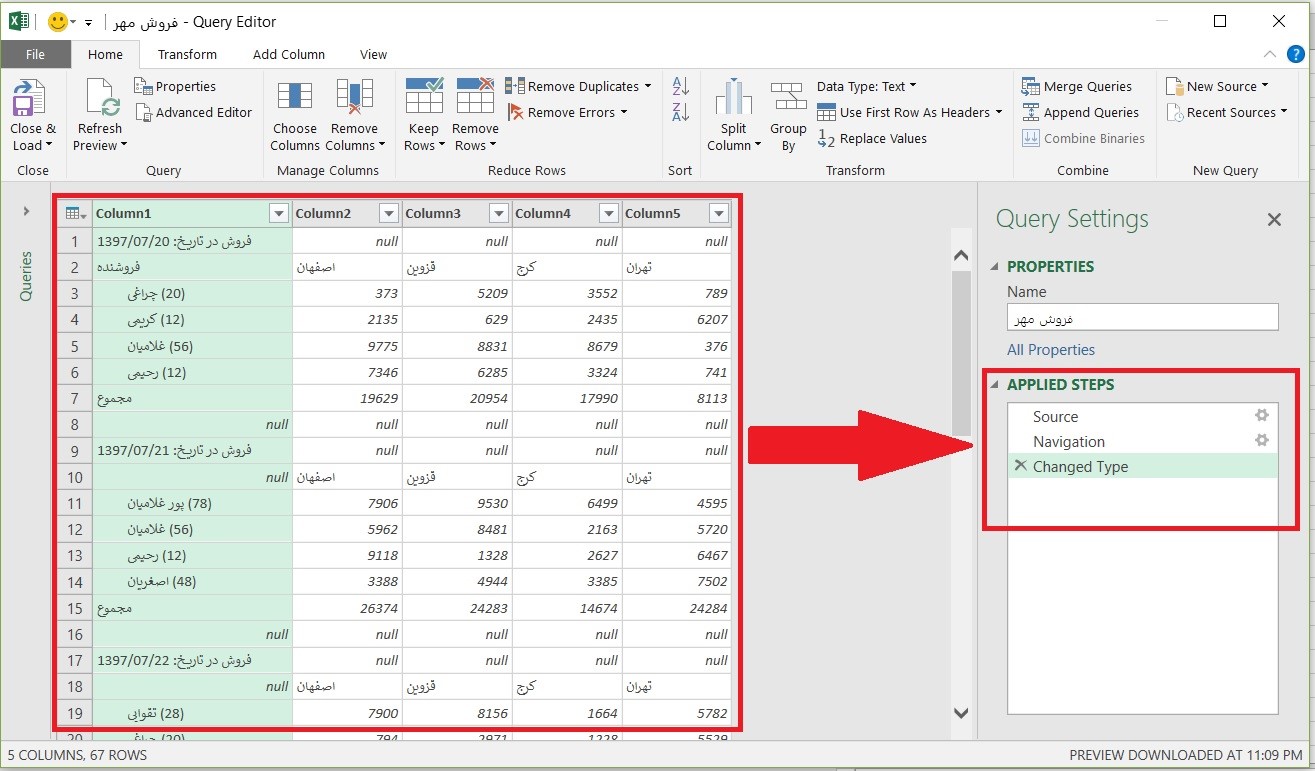
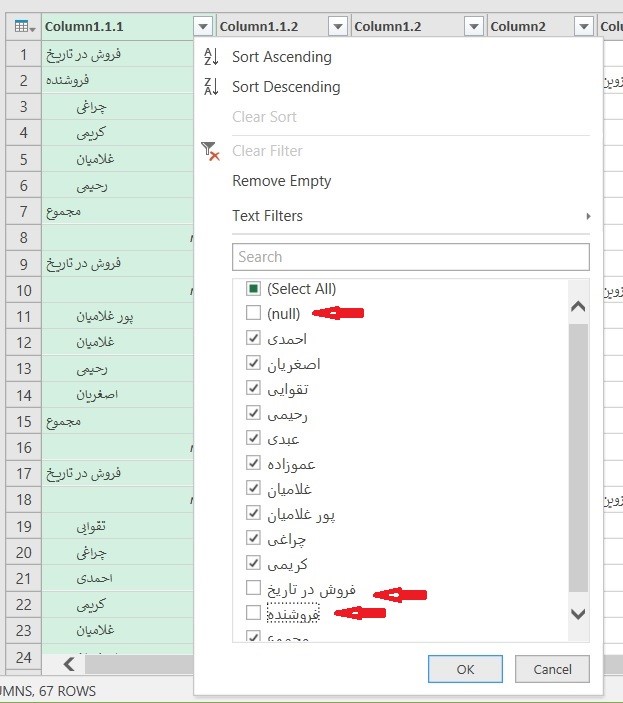
۳- در فضای پاور کوئری بر روی زبانه کوچک کنار ستون Abadi_Name کلیک کرده و تیک کنار Null را برداشتم. با این کار تمام سطرهای حاوی مقدار Null حذف میشوند. در نهایت Load and Close را کلیک کردم تا به فضای اکسل بر گردم.

بعد از پاکسازی دادهها، باید سلسله مراتب یا Hierarchy ساخته شود. سلسله مراتب یا Hierarchy همان چیزی است که باعث میشود تا این دادههای تخت یا Flat در سطوح مختلف یا سلسله مراتب مختلف مانند تصویر ابتدای مقاله نمایش داده شوند. برای ساخت سلسله مراتب یا Hierarchy مراحل زیر را انجام دادم.
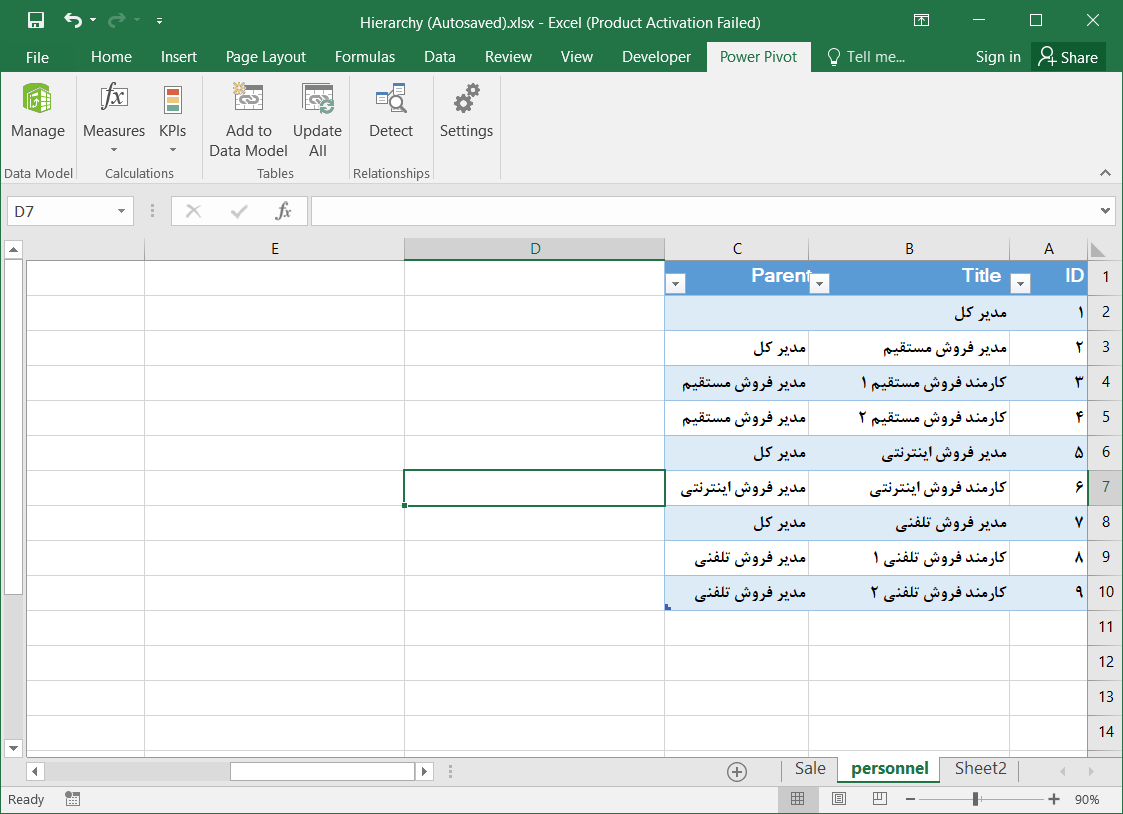
۱- ابتدا دادهها را انتخاب کرده و سپس از تب Power Pivot گزینه Add to Data Model را انتخاب کردم.
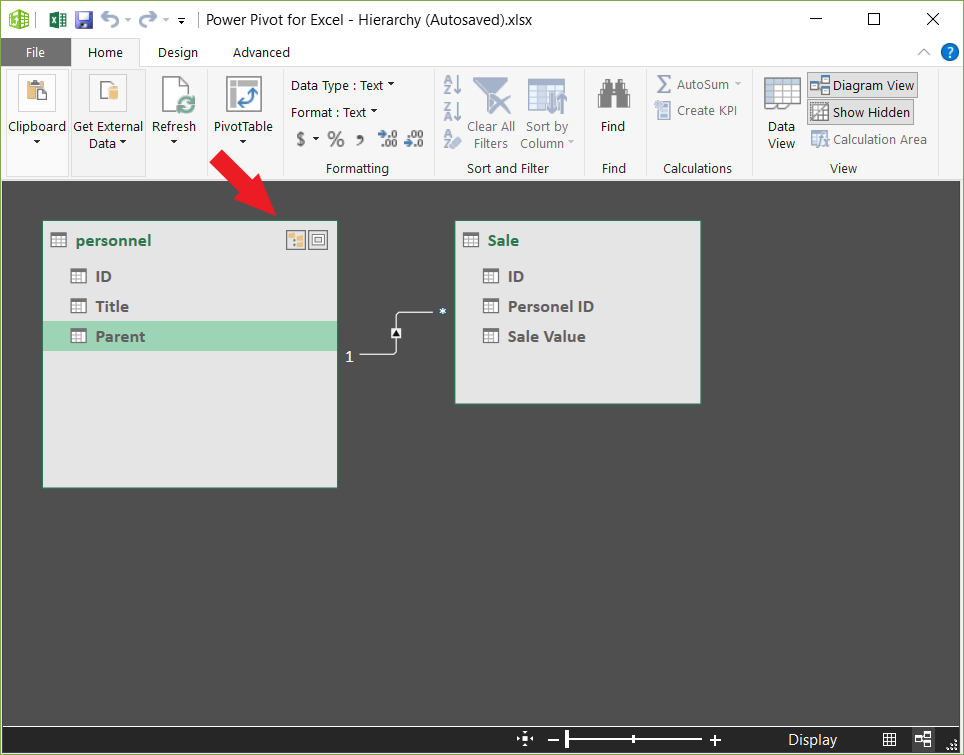
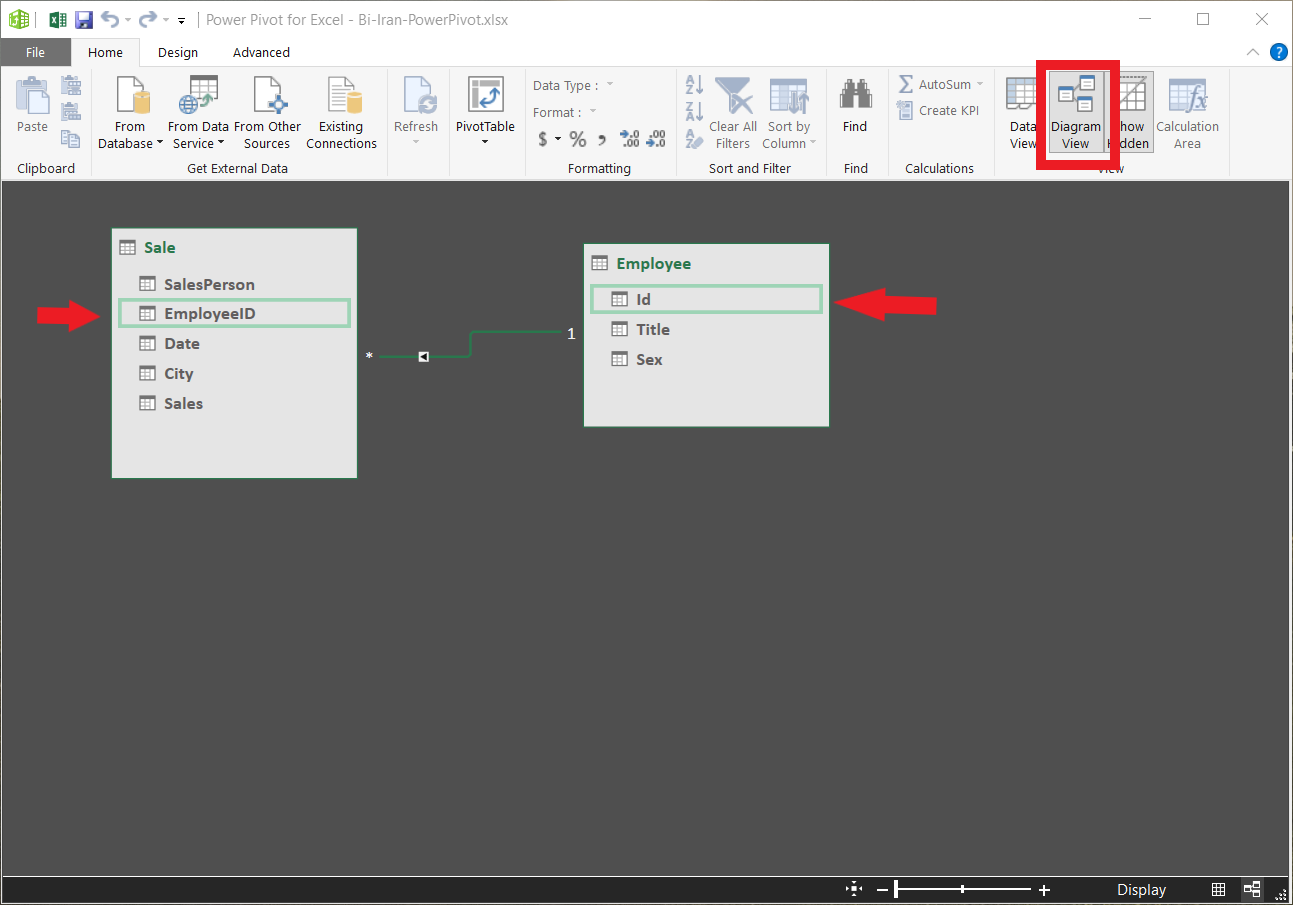
۲- سپس نحوه نمایش را به Diagram View تغییر دادم.
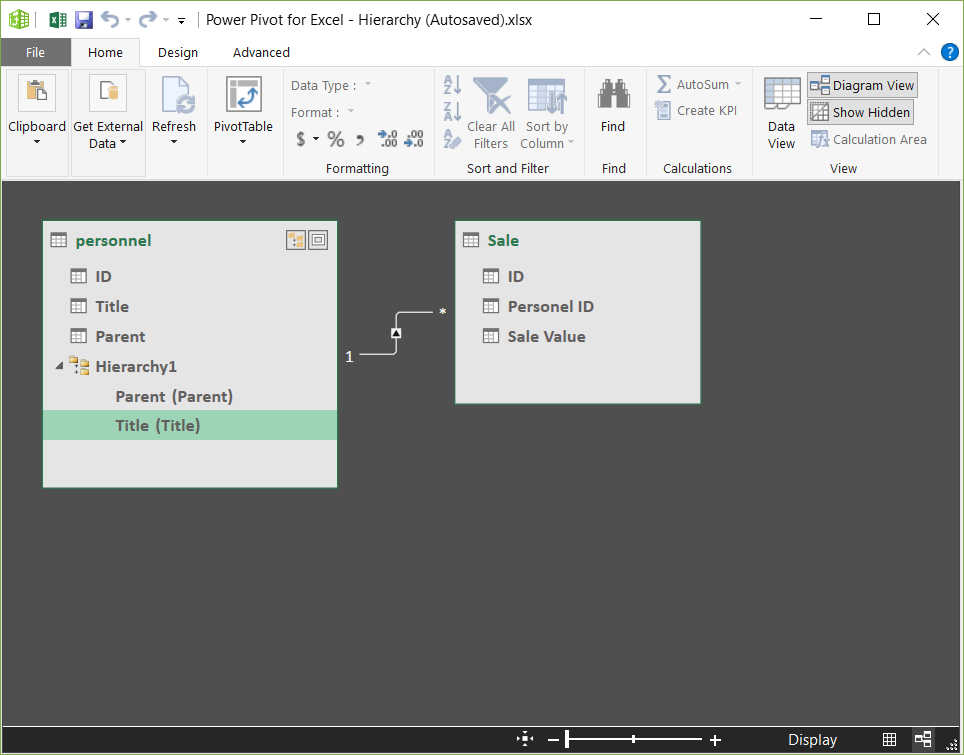
۳- بر روی علامت گوشه بالا سمت راست جدول کلیک کرده و نام Hierarchy را به GEO تغییر دادم و سپس به ترتیب نام ستونهای Ostan_Name, Shahrestan_Name, Bakhsh_Name, Dehestan_Name, Abadi_Name را درگ کرده و بر روی نام Geo رها کردم. سلسله مراتب ساخته شد.
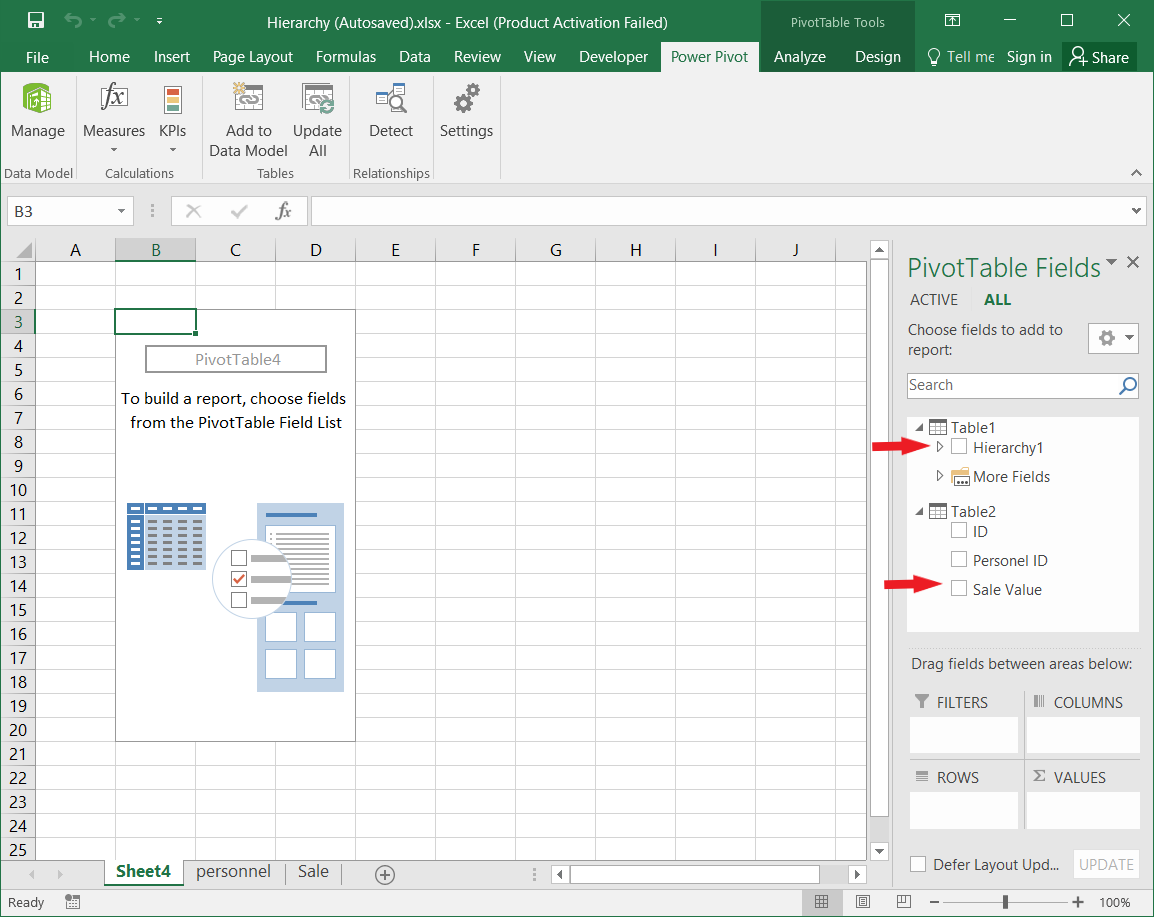
۴- بر روی Pivot Table کلیک کردم.
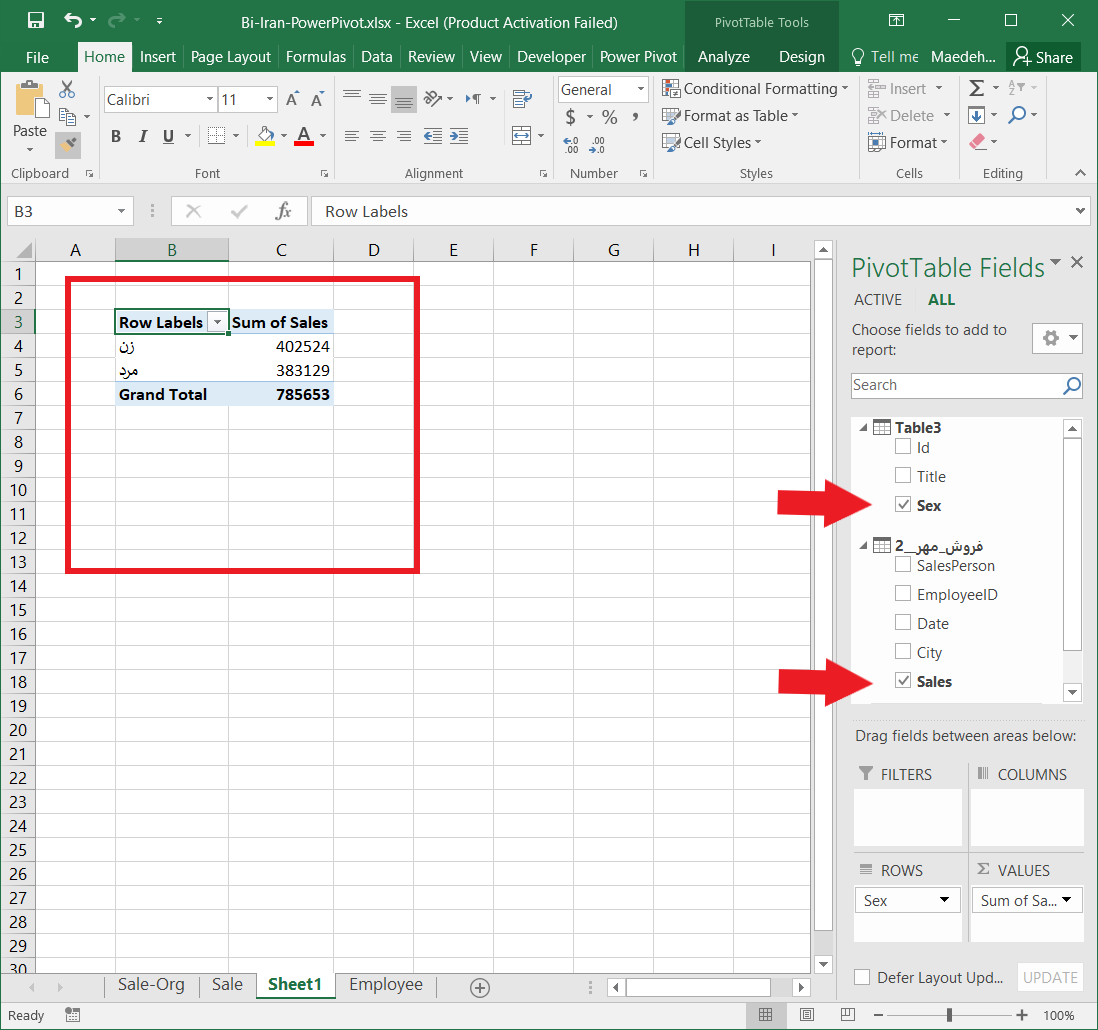
۵- گزینه GEO را در Pivot Table Field تیک زدم تا سلسله مراتب استان، شهرستان، بخش، دهستان و آبادی نمایش داده شود.

فایل اکسل نهایی را میتوانید از اینجا دانلود کنید.