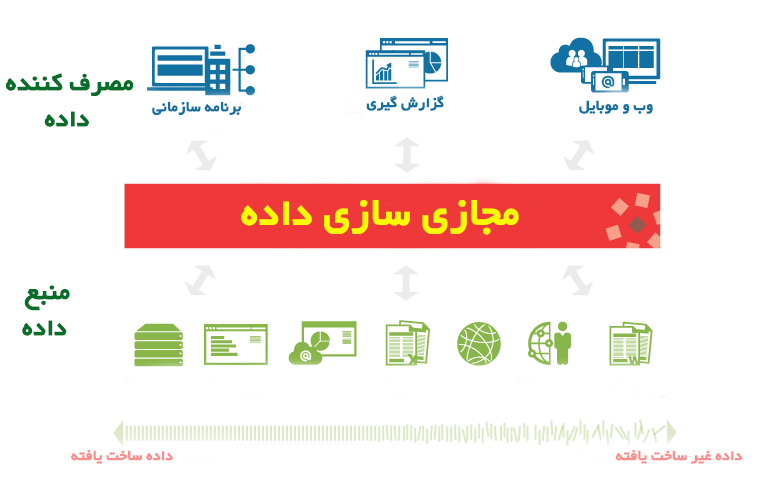
مجازی سازی داده (Data virtualization): در مجازی سازی، داده ها از منابع مختلف و فرمت های مختلف با هم ترکیب می شوند تا یک لایه مجازی را برای افراد و برنامه های مختلف ایجاد کنند. در مجازی سازی داده، نیازی به طی کردن فرآیند ساخت انبارداده و عملیات ای تی ال نیست و افراد درگیر جزئیات فنی در خصوص داده (مانند فرمت داده یا محل ذحیره سازی آن) نمی شوند. در مجازی سازی داده های غیر ساخت یافته مثل وب یا متن هم وجود دارد.
انتقال داده (Data movement): در انتقال، داده ها از منابع مختلف استخراج می شود و با کمک فرآیند ای تی ال (ETL) به یک انبار داده منتقل می شود. وجود انبار داده و انجام فرایند ای تی ال در انتقال داده ضروری است. در انتقال داده، داده های غیر ساخت یافته مانند متن یا وب وجود ندارد.
چه زمان هایی از مجازی سازی داده استفاده کنیم و چه زمانی از انتقال داده؟
زمانی که دیتاست های مختلف با هم جوین (Join) می شوند و سرعت و کارایی باید بسیار بالا باشد، از انتقال استفاده می کنیم.
زمانی که داده ها فقط یک بار در بازه های مختلف به انبار داده منتقل می شوند و بارها از آنها گزارش تهیه می شود، از انتقال استفاده می کنیم.
و در مورد تعداد زیادی کوئری موردی، بدون اجبار به سرعت بالا، از مجازی سازی داده استفاده می کنیم.
مجازی سازی داده چه مزایا و چه معایبی دارد؟
در مجازی سازی، عملیات ای تی ال انجام نمی شود بنابراین سربار جابجایی داده ها به شدت کاهش پیدا می کند. سرعت دسترسی به داده ها، به صورت بلادرنگ به طرز چشمگیری افزایش پیدا می کند (البته با این فرض که جوین (Join) های سنگینی بین جداول وجود نداشته باشد.). زمان توسعه و پیشتیبانی کاهش پیدا می کند. و فضایی جهت انبارداده لازم نیست.
از طرف دیگر به علت عدم استفاده از انبار داده، سوابق داده ها را به خوبی نگهداری نمی کند. یک مدل داده همگن را بکارنمیگیرد. بنابراین باید خود کاربر داده ها را تفسیر کند، مگر اینکه با مدل های دیگری ترکیب شده باشد. مدیریت تغییرات سربار بسیار زیادی دارد. زیرا هر تغییر باید توسط تمام برنامه های کاربردی و کاربرانی که داده با آنها به اشتراک گذاشته شده است مورد پذیرش قرار گیرد.